This has been quite a busy month, especially on the programming front. On the good side of things, I have made some headway in the image-to-text project I previously mentioned. On the other hand, my teammate and I really need to hasten our work, and complete our project within the next two months. There is much to do, in so little time!
This project has also opened my mind about Python codes, and has given me compelling reasons to continue learning more about it. Being a staunch C++ programmer since my high school days, it took me quite some time to realize its immense value in today’s computer systems, and gain confidence in it .
Python – an introduction
Python was released by Guido van Rossum in 1991. An ardent fan of Monty Python’s Flying Circus, Van Rossum initiated it as a hobby project in December 1989, as an interpreter for ABC, another programming language at the time. Python eventually became an interpreted language in its own right, and now has a large developer base, spread all over the planet.
One reason for its global appeal is its strong emphasis on keeping lines of code as readable and clutter-free as possible. This is implemented by PEPs (Python Enhancement Proposals) – design documents that provide the rationale behind a feature, and its technical specifications.
The strict adherence to readability in Python is obvious from the fact that it lacks any curly braces or semicolons for indentation, and completely relies on the use of tabs and spaces for the same. This, unfortunately, acts as a double-edged sword, since Python is unforgiving when programmers add too many or too little spaces, or use a mix of spaces and tabs in their code. More often than not, Python code developed by rookie programmers will not run, due to incorrect indentation. Hence, it might help to go through the PEP 8 guide, and correct all indentation errors in the code.
Nevertheless, Python has become immensely popular over the last few decades, and continues to go mainstream, so much that de-facto libraries like OpenGL, OpenCL, Unity and TensorFlow have all been developed in C++, and are available for integration with Python, using wrappers.
What are wrappers?
Wrappers are interfaces that allow a program to build on to an existing piece of code or program, without disturbing it. This allows the programmer to extend the capabilities of a program, or a portion of it, while hiding a few features of the original program (abstraction). Hence, the portability of the program code is increased.
Through wrappers, Python lifts a big burden off the programmer’s shoulders, since he or she no longer has to translate the entire code into another language, and simply has to decide what features to include, and which ones to exclude, while designing the new interface.
Python wheels – libraries installed using pip
Another reason why I am impressed by Python modules is their ease of installation. With just a single ‘pip install’ command in Terminal, a user can download and install any Python library he or she needs, and deploy it immediately.
This has been made possible through wheels – a packaging format created by the Python community. These are maintained on PyPI (Python Packaging Index), Python’s official repository for third-party software. With its origins dating back to September 2000, it continues to grow and improve to this day. It currently houses over 100,000 packages, enough for a programmer to be spoilt for choice.
On the other hand, a C/C++ user, more often than not, is expected to manually download a zipped file from the Internet, decompress it, and build it from source – an unpleasant and tiresome experience in my past programming ventures. Undoubtedly, Python programmers are at an advantage over here!
Tuples
One data type that piqued my interest was the ‘tuple’, a concept borrowed from mathematics. It is a finite sequence of elements. It is extremely valuable in creating CSV files, and computational mathematics, especially matrix operations.
At this point, many of you might be wondering, “Even if all its elements are numbers, a tuple is just a row matrix. How is computational mathematics going to benefit from tuples?”
Enter the matrix
To counter this thought, I shall now share an example, from my project. Remember the colour images I wished to convert to grayscale? Well, that requires each pixel of the image to be read as a matrix, and what better way to do that than by tuples!

Here is some of the pixel information of this image, in matrix notation:
[[[ 71 65 53]
[ 73 67 55]
[ 76 70 58]
…
[168 178 143]
[166 176 139]
[164 174 137]]
[[ 58 48 38]
[ 57 47 37]
[ 55 45 35]
…
[221 215 199]
[221 215 199]
[221 215 199]]]
Though it is only part of the whole image, it is clear that each pixel is represented as a tuple of three elements. These elements are the red(R), green(G) and blue(B) values corresponding to their pixels. Python needs to read the image as a matrix of three-element tuples, before any kind of image manipulation can be done.
Taking this matrix of tuples, the image gets converted to grayscale using a simple formula, that computes the average of the R,G and B values of each pixel.
This causes the program to generate this output:

By the way, here is the complete Python program, if you wish to have a look:
https://github.com/the-visualizer/image-to-text/blob/master/img2grey.py
Note: Although the saved grayscale has the same resolution as the colour input, the pyplot function is generating this output on my machine, for some unknown reason.
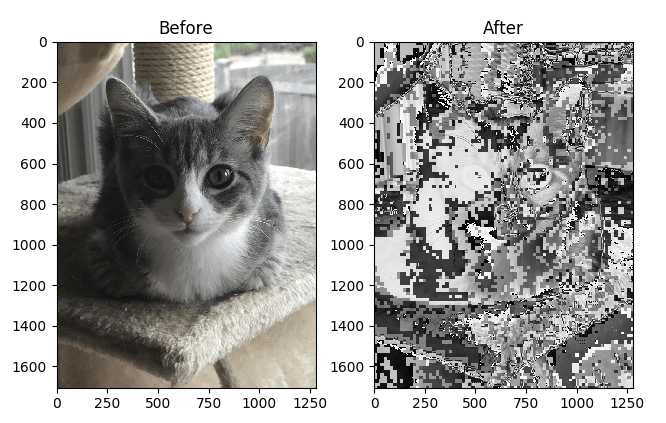
I suspect it is caused by a missing module from my machine, since it works fine on my friend’s laptop. Hopefully, I shall fix this bug soon!
External Links
- PEP 8 – the Style Guide for Python code:
- Function wrapper and python decorator; a blog post:
https://amaral.northwestern.edu/blog/function-wrapper-and-python-decorator
- Tuples; a chapter in How to Think Like a Computer Scientist: Learning with Python 3:
http://openbookproject.net/thinkcs/python/english3e/tuples.html
- RGB to Grayscale Conversion; a tutorial:

